探寻大语言模型 Agent 测评:解读其底层逻辑
在 AI 圈,大语言模型测评堪称「玄学现场」:某国产模型在 C-Eval 榜单力压 GPT-4 登顶,却在真实金融咨询中频繁输出过时政策;GPT-4 能考过律师资格考试,却在小学数学题的数字微调后正确率暴跌 10%。当模型从「专项选手」进化成「全能 Agent」,传统测评体系正在经历前所未有的颠覆。
在传统测评体系中,我们所进行的任务都是标准化的,比如图片分类、文本抽取、情感判断等。这些任务都有固定的框架和标准输出结果。我们可以通过一些指标来评估模型的性能,比如准确率、召回率、F1 分数等。
但是,当大语言模型的到来,模型的能力不再是标准化的,而是不断在扩展,从AI写作、图像生成到AI编程,模型可以完成各种各样的任务。同时,这些任务的输出结果好坏也是多层次的,很多时候也是因人而异的。这就导致,传统的测评体系已经无法满足需求。
大语言模型 Agent 作为连接技术与场景的桥梁,通过集成LLM的理解、推理与决策能力,已在客服、医疗、金融等领域实现自动化任务处理。其测评不仅是技术验证,更是商业落地的关键风控环节,直接影响用户体验与业务效率。
02. 大语言模型Agent测评基本流程?
那么对于大语言模型Agent的测评,我们该如何进行呢?
这里引用 TinyEval 项目中的一张图讲述整体流程:
测评任务流程图
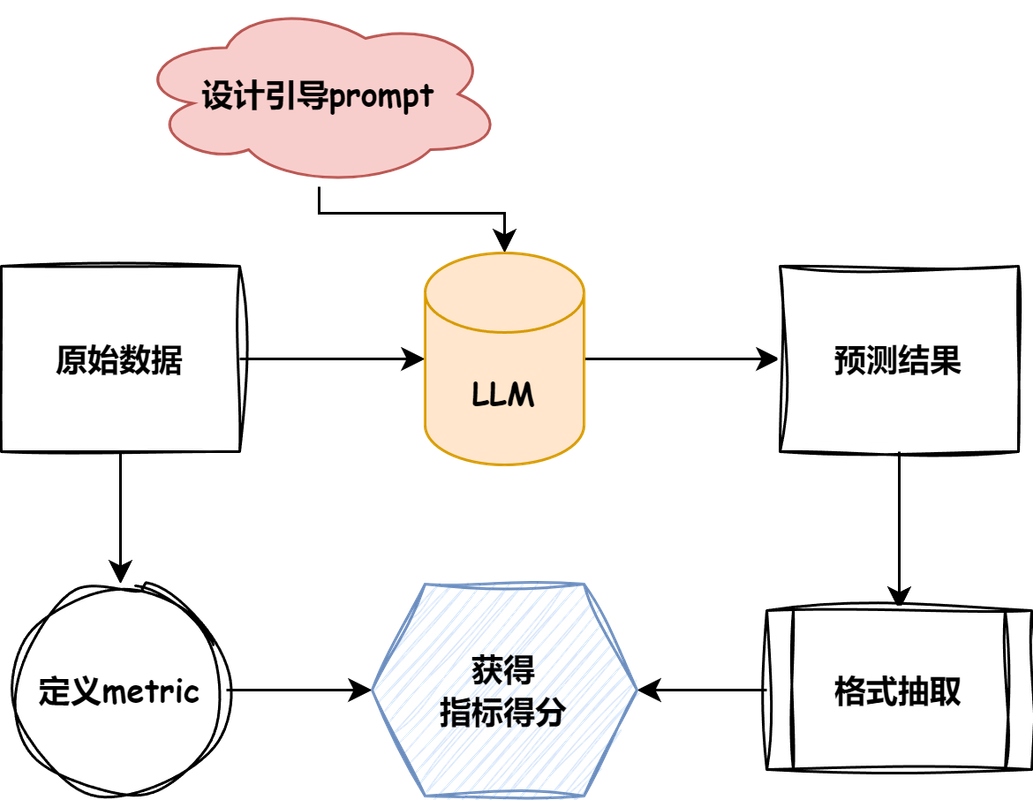
- 首先,需要找到合适的数据集,并通过数据集的任务类型指定合适的测评指标
- 针对数据集和LLM,设计引导提示词,并进行推理
- 根据交互结果,设计合理的抽取方式,基于模型的推理结果和数据集的预期结果计算测评结果
这就是大语言模型Agent测评的基本流程。
03. 如何构造适合业务的测评流程?
怎么选数据集?
若针对已有的业务构建Agent以优化人工成本,数据集可利用现有的业务数据来构建,尽可能广泛地涵盖各类边界数据,如此便能提升Agent的稳定性。
要是面对的并非现有业务,而是全新业务,又该如何构建数据集呢?
在此谈谈我的一些思考。
首先,探寻是否存在现成的开源数据集,若能找到目标一致的数据集,那自然再好不过。
若没有现成的数据集,那就考虑能否通过改造已有的数据集来满足需求。
例如,我们打算构建一个代码审查的Agent,然而当前并没有专门用于代码审查的数据集。
当下较多的是代码生成的数据集。于是,我们可以将问题与答案进行反转,把数据集中的答案当作代码审查的问题,把数据集中的问题当作代码审查的答案。
如此一来,便得到了一个适用于代码审查的数据集。
怎么选指标?
指标主要取决于答案的长度,按答案的长度可以分为以下三类指标:
| 答案长度类型 | 常用测评指标 | 说明 |
|---|---|---|
| 单选/多选 | 准确率(Accuracy) | 适用于有标准答案的选择题,统计预测与真实标签一致的比例 |
| 简短文本 | F1 分数 (基于分词后token计算) | 适用于简答题、抽取式问答,衡量生成文本与参考答案的重合度 |
| 长文本 | BLEU、ROUGE | 适用于生成式问答、写作等,BLEU/ROUGE关注字面重合 |
我们根据数据集的类型,选择合适的指标即可。
怎么设计提示词?
提示词的设计,主要取决于数据集的类型。下面给一个TinyEval中的例子:
阅读以下文字并用中文简短回答: {context} 现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。 问题:{input} 回答:
提示词设计时,常常会把数据集中的内容置于提示词中间,接着让模型依据提示词展开推理。
但这里存在一个问题:要是数据集中的内容篇幅过长,就会致使模型的上下文长度不够,使其无法读取到末尾的内容。
所以,在上述例子里,我们有必要对context进行截断处理,防止超出模型的上下文长度限制。
总结
今天,我们探讨了大语言模型Agent测评的底层逻辑,涵盖了数据集的选择、指标的选取以及提示词的设计。
接下来,我们将着手实践,构建一个面向代码审查的大语言模型Agent的测评流程。
希望这能对大家有所帮助。
参考链接: