之前有多嫌弃大模型框架,现在用 LangGraph 就有多香
聊到大模型框架,你是不是也和我曾经一样,觉得 LangChain 这类东西有点‘多此一举’?总感觉自己写几行 Python 代码就能搞定一切。
我之前就是这么想的,直到我遇到了 LangGraph... 妈耶,真香!它解决工具调用问题的丝滑程度,让我这个‘手搓党’都直呼好家伙。今天,我就带大家一起体验下这种快乐,顺便聊聊我踩过的坑。
官方的教程分了6步,今天我们先拿下前三步。可以说,会了前三个,就可以解决 80% 的 Agent 开发问题了。
- 构建一个基础聊天机器人 (Build a basic chatbot)
- 为它添加工具 (Add tools)
- 赋予它记忆 (Add memory)
- (进阶) 添加人工循环 (Add human-in-the-loop controls)
- (进阶) 自定义状态 (Customize state)
- (进阶) 时间旅行 (Time travel)
那我们就开始吧!🚀
Langgraph 的基本概念
如果说 LangChain 是一种大模型的开发“套件”,那么 LangGraph 就可以看作是一种专门构建 Agent 的“蓝图”。它在维度上比 LangChain 更高一级。
我们可以先看看 LangGraph 是如何理解 Agent 的。官方是这么定义的:
智能体 (Agent) 由三个组件组成:大型语言模型(LLM)、一组工具和提供指令的提示(prompt)。 LLM在循环中运行。在每次迭代中,它都会选择一个要调用的工具,提供输入,接收结果(观察),并使用该观察来告知下一个操作。循环会一直持续到满足停止条件——通常当智能体收集了足够的信息来响应用户时。
Langgraph 整体是一个 有向图(Directed Graph),可以包含多个节点,每个节点都代表一个函数,节点之间通过有向边连接,有向边代表函数之间的转换。
- State: 它是一个共享的数据结构,用来保存整个图的当前状态,比如对话历史、工具调用结果等,所有节点都可以读取和更新它。一般大模型的上下文都是保存在 State 中。
- Node: 节点表示一种处理逻辑的函数,它们接收当前状态作为输入,在执行完成后,返回更新后的状态。Node 可以定义各种逻辑,比如执行大模型推理、调用工具等。它接收当前
State作为输入,返回更新后的State - Edge: 节点之间通过有向边连接,有向边代表状态之间的转换
在 Langgraph 中定义好 有向图 之后,也就完成了 Agent 的开发,它还支持绘制 有向图 的图形,方便我们快速了解 Agent 的结构。
下面我们就利用上面这三个元素,开始第一步的学习。
第一步:Build a basic chatbot
让我们从一个最简单的聊天机器人开始。LangGraph 的核心是状态管理,所以我们首先需要定义状态结构和节点函数。
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
from typing import Annotated, Callable, Any, Dict
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from config import AgentConfig
main_agent_config = AgentConfig(
model_name="Doubao-1.5-lite-32k",
temperature=0.1,
max_tokens=4000,
)
class State(TypedDict):
messages: Annotated[list, add_messages]
if __name__ == "__main__":
graph = StateGraph(State)
llm = ChatOpenAI(
model=main_agent_config.model_name,
temperature=main_agent_config.temperature,
max_tokens=main_agent_config.max_tokens,
openai_api_key=main_agent_config.openai_api_key,
openai_api_base=main_agent_config.openai_base_url,
)
def chat_node(state: State):
result = llm.invoke(state["messages"])
return {"messages": [result]}
graph.add_node("chat", chat_node)
graph.add_edge(START, "chat")
graph.add_edge("chat", END)
app = graph.compile()
result = app.invoke({"messages": [{"role": "user", "content": "你好呀朋友"}]})
print(result.get("messages", [])[-1].content)
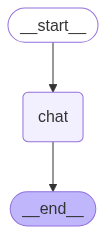
看,我们定义了一个 chat 节点,然后把 START(起点)和 END(终点)这两个特殊节点连接到它上面,就完成了整个图的构建。每个 LangGraph 都会有 START 和 END 节点,作为 Agent 的起点和终点。
这个简单的例子展示了LangGraph的基本结构:状态定义、节点函数、图构建和编译。
还可以执行 app.get_graph() 来获取图的结构,这对于调试复杂流程非常有帮助。
# 生成图的可视化图片
graph_image = app.get_graph().draw_mermaid_png(output_file_path="agent_graph.png")
Agent基本流程图
第二步:Add tools
现在让我们添加工具调用能力,这是Agent的核心功能。
和之前手写 ReAct 框架不同,使用 LangGraph 调用工具十分简单,我们只需要定义一个专门处理工具调用的节点,并设置好条件路由(Conditional Edges)即可。
tools = [Tools.google_search, Tools.code_check]
llm_with_tools = llm.bind_tools(tools)
def chat_node(state: State):
result = llm_with_tools.invoke(state["messages"])
return {"messages": [result]}
graph.add_node("chat", chat_node)
graph.add_node("tools", ToolNode(tools))
graph.add_edge(START, "chat")
graph.add_conditional_edges(
"chat",
tools_condition, # Routes to "tools" or "__end__"
{"tools": "tools", "__end__": "__end__"}
)
graph.add_edge("tools", "chat")
graph.add_edge("chat", END)
app = graph.compile()
result = app.invoke({"messages": [{"role": "user", "content": "你好呀朋友"}]})
print(result.get("messages", [])[-1].content)
我们新增了一个 tools 节点,并用 add_conditional_edges 定义了条件:当 chat 节点输出的消息包含工具调用请求时,流程就走向 tools 节点;否则就走向 END。工具执行完毕后,再流回 chat 节点,形成一个循环。
我们再来看看现在的图结构:
Agent和工具节点流程图

第三步:Add memory
一个能记住对话历史的 Agent 才算得上是合格的。LangGraph 的记忆模式一共提供了两种,短期记忆和长期记忆。
短期记忆
短期记忆主要保存了当前对话的上下文,包括了用户的问题和Agent的回答。
短期记忆主要挑战是,长对话难以存储,如何管理长上下文还是一个值得研究的问题。
在 LangGraph 中,短期记忆是基于 Checkpointer 来实现的。下面看一下具体的实现方式。
最后添加记忆功能,让Agent能够记住对话历史,首先创建一个记忆体。教程里面使用的 InMemorySaver,我们使用SqliteSaver来尝试下。
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
conn = sqlite3.connect("checkpoints.sqlite", check_same_thread=False)
memory = SqliteSaver(conn)
app = graph.compile(checkpointer=memory)
除此之外,在推理时,还需要添加如下的config配置,使用 thread_id 来表示对话的唯一性。
config = {"configurable": {"thread_id": "1"}}
result = app.invoke(
input = {"messages": [{"role": "user", "content": "你好呀朋友"}]},
config = config
)
我们来尝试下记忆功能的效果如何:
user: 我是代码里程碑,你记住了吗?
assistant: 用户表明身份为代码里程碑,希望调用具有记忆功能的工具来记住用户身份,但当前工具列表中没有此类工具,因此直接回答用户。记住啦,你是代码里程碑。 请问你有代码相关的问题需要我帮忙吗?比如要不要调用 `code_check` 工具来检查一段代码?你可以告诉我代码的语言类型和具体内容。
user: 你知道我是谁吗?
assistant: 你是代码里程碑呀。 如果你有代码相关需求,比如想检查某种语言的代码是否存在问题,我可以帮你调用 `code_check` 函数,你只需要告诉我代码的语言类型和具体代码内容就行。
✅ 成功!Agent 已经能记住我们的身份了。LangGraph 的记忆机制通过 thread_id 自动管理了会话状态的存取,非常方便。
长期记忆
LangGraph 中的长期记忆允许系统在不同对话或会话中保留信息。与短期记忆不同,长期记忆保存在自定义的"命名空间"中。
长期记忆在Langgraph中主要使用了store来实现。典型实例是 InMemoryStore。
长期记忆主要是通过业务自己来实现的,官方文档给出了一个思路框架,如下的类别内容可以通过长期记忆来保存:
语义记忆:记住事实或概念,用于个性化。
情景记忆:记住如何完成任务的步骤。
程序性记忆:记住执行任务所使用的规则。
这三类记忆官方建议通过长期记忆来保存。下面我们也来实际看一下,如何通过长期记忆来实现。
长期记忆保存类似于字典的存储方式,我们需要定义 namespace、key、value。
读取时,通过 namespace 和 key 来精确获取 value。或者通过语义检索的方式,通过namespace、query来获取value。
下面是一个使用长期记忆的例子:
embeddings = AIHubMixEmbedding()
store = InMemoryStore(index={"embed": embeddings, "dims": 1536})
namespace = ("users", "memories")
store.put(
namespace,
"user_123",
{
"name": "John Smith",
"language": "English",
"food_preference" : "I like pizza",
}
)
store.put(
namespace,
"user_124",
{
"food_preference" : "I like apple",
}
)
def get_rules(query: str)-> str:
"""
获取用户规则, 用于回答用户问题
"""
from langgraph.config import get_store
return get_store().search(namespace, query=query, limit=1)
tools = [get_rules]
llm_with_tools = llm.bind_tools(tools)
app = graph.compile(store=store)
result = app.invoke(
input = {"messages": [{"role": "user", "content": "do you know my name?"}]},
config = config
)
print(result.get("messages", [])[-1].content)
graph 在编译时传入的 store 就是长期记忆的存储。可以在任何地方通过 get_store() 来获取 store,然后进行保存和检索。
说实话,我感觉这个内置的长期记忆功能有点“鸡肋”。它本质上是提供了一个基础的 RAG 能力(存储、语义检索),但功能比较初级。如果你的项目中已经有更强大的外部 RAG 系统,我更建议直接在工具函数(如 get_rules)里调用你自己的 RAG 服务。
对了,还有个蛋疼的事情,AIHubMixEmbedding 是我自己实现的,Langchain 只有 openai 官方的嵌入器,如果你用的不是官方的接口,就要自己实现了。
总结
所以,LangGraph 到底‘香’在哪里呢?我总结了几个让我爱不释手的点:
- 流程控制灵活:支持条件分支、循环等复杂流程控制
- 工具集成简单:工具调用逻辑更加可靠,减少了提示词工程的工作量
- 记忆功能强大:内置短期记忆和长期记忆,方便管理对话状态
通过这三个步骤,你已经掌握了LangGraph的核心用法。下一步可以探索更高级的功能,如人类参与控制、自定义状态管理和时间旅行等特性。
LangGraph 确实是一个强大的 Agent 开发框架,它让复杂的多步骤推理变得更加可控和可靠。对于需要调用多个工具、维护对话状态的场景,LangGraph 绝对是构建复杂 Agent 的一把瑞士军刀。希望这篇入门能帮你打开新世界的大门!
🛠️ 本文所有代码都已开源在我的 TinyCodeBase 仓库中:TinyCodeBase,欢迎大家给个 star 持续关注。你的每一个反馈都是我持续创作的最大动力!✨”