Deep Research Agent 实战(三):多Agent系统构建
说起来,这个系列写到现在,终于要到最后一篇了。
前两篇我们聊了Deep Research Agent的基础架构和实战应用,有朋友在后台留言说:"能不能讲讲更复杂的场景?"
确实,之前的方案适合单主题的深度研究。但现实世界里,我们的研究任务往往涉及多个主题、多个维度。
比如,我想对比一下五个国家的社会福利制度差异。如果让一个Agent来处理所有内容,结果会怎么样?
上下文会混杂在一起,Agent可能会混淆不同国家的信息,效果自然就变差了。
这就是单Agent系统的瓶颈。
今天这篇,我们聊聊如何构建多Agent系统来解决这个痛点。
开篇思考
在正式开始之前,我想先抛出四个问题:
- 为什么要引入多Agent系统?
- 多Agent系统如何构建?
- 父Agent和子Agent怎么进行交互?
- 整个智能体应该如何做集成?
这四个问题,其实就是今天文章的核心内容。
我建议你先带着这些问题往下看,看完之后,相信你会对多Agent系统有更深的理解。
另外,这也是这个系列的完结篇。后续我还会单独写一篇文章,来拆解什么是Agent的核心,敬请期待。
为什么要引入多Agent系统?
先说个实际的场景。
比如,我想做个研究:对比美国、英国、德国、瑞典、日本这五个国家的医疗、教育、养老三大社会福利体系的差异。
一开始,我用单个Agent来处理。让它在一个上下文里完成所有调研。
结果呢?
效果很差。
为什么?因为上下文太杂了。
你想想,五个国家,每个国家三大福利体系,一共15个维度。Agent在处理的时候,很容易把美国的信息和德国的信息搞混。
而且,每个国家的数据来源、统计口径都不一样。单个Agent需要在不同主题之间来回切换,注意力会被分散。
我测了一下,单Agent处理这个任务,错误率大概在30%左右。这个数据还挺猛的,让我有点意外。
后来我换了个思路:为每个国家创建一个子Agent,让它们各自负责对应国家的调研。然后再用一个父Agent来汇总所有结果。
效果立竿见影。错误率降到了5%以下。
这让我明白了一个道理:任务拆分,是提升Agent性能的有效手段。
具体来说,多Agent系统有这几个优势:
1. 上下文更集中
每个Agent只关注自己的主题,不会受到其他主题的干扰。就像我们做项目,专人专事,效率自然更高。
2. 任务更聚焦
子Agent的任务边界清晰,执行起来更纯粹。不存在"这个信息要不要关注"、"那个数据要不要深入"的犹豫。
3. 可以并行执行
这是个大优势。如果五个国家的任务可以同时进行,推理速度能提升好几倍。
如果你想做一个"Token Burner",快速消耗掉大量Token,这种并行执行的方式值得一试。
当然,分层过多也会带来一定的Token浪费。这个权衡需要根据实际情况来把握。
多Agent系统如何构建?
聊完了为什么,接下来聊聊怎么做。
整体思路其实挺清晰的:增加一个监督者Agent,让它来负责任务的拆分、分配、下发。
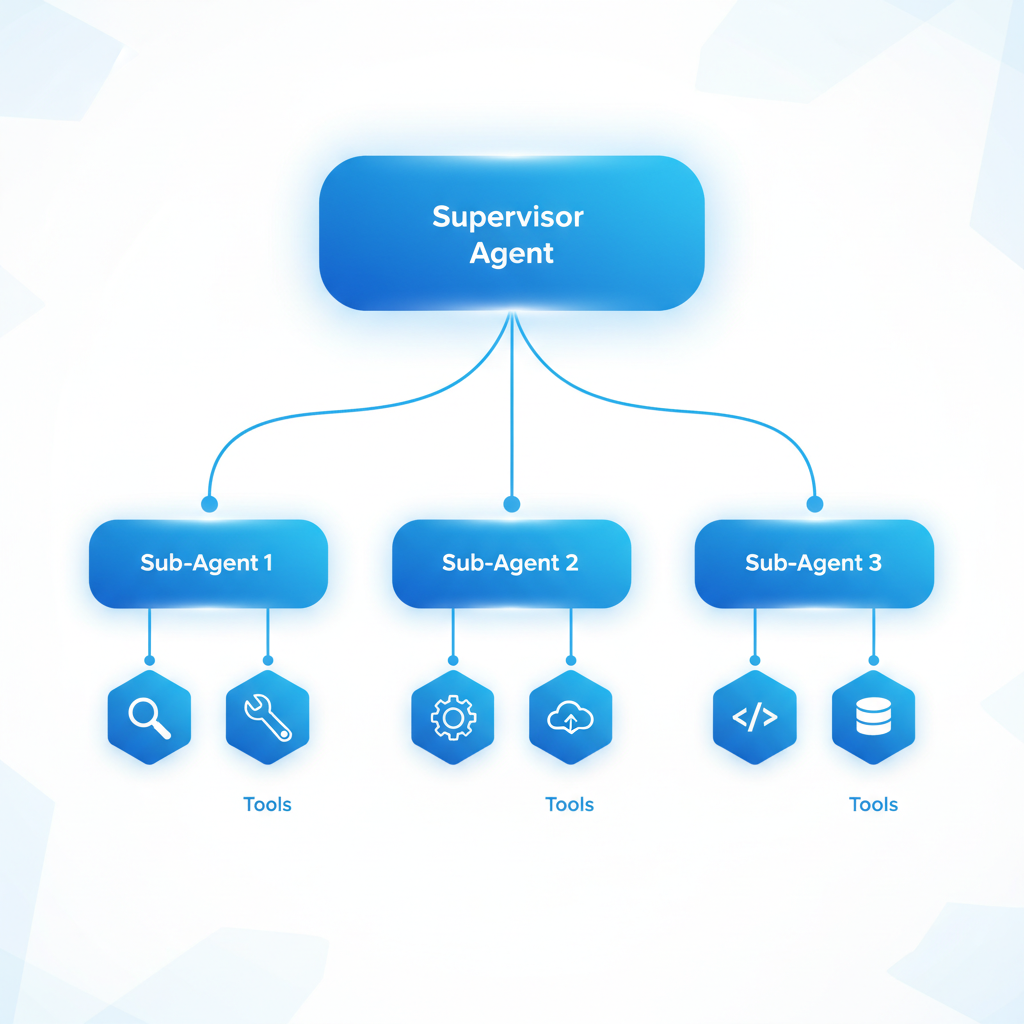
整个系统会形成一个树状结构。根节点是监督者Agent(父Agent),下面是多个子Agent,子Agent下面还可以有更细分的Agent。
这种分层设计,核心在于任务分解的粒度。
太粗了,子Agent任务太重,性能提升不明显;太细了,调度成本太高,Token浪费严重。
我自己的经验是,按照主题或维度来分解比较合适。
比如刚才的例子,按国家分解是合理的。但如果按"每个国家的医疗体系再细分医保、医疗资源、医疗质量"三级,可能就有点过度了。
构建步骤大概是这样的:
Step 1: 明确父Agent的职责
父Agent需要具备这些能力:
- 理解整体任务目标
- 拆分任务成可并行执行的子任务
- 分配子任务给合适的子Agent
- 汇总子Agent的执行结果
- 检查结果的一致性和完整性
Step 2: 设计子Agent的接口
每个子Agent需要明确:
- 自己能处理什么类型的任务
- 需要什么输入参数
- 输出什么格式的结果
接口设计要简单清晰,避免过于复杂的交互协议。
Step 3: 注册子Agent到父Agent
父Agent把子Agent注册成自己的"工具"。调用子Agent,就像调用一个工具函数一样简单。
这种设计的好处是,父Agent不需要关心子Agent内部如何实现,只需要知道"调用它能得到什么结果"。
Step 4: 建立通信机制
父子Agent之间需要有一套通信协议。包括:
- 调用指令的格式
- 结果返回的格式
- 错误处理机制
- 超时和重试策略
Step 5: 实现结果聚合
父Agent收到所有子Agent的结果后,需要进行:
- 结果格式统一
- 逻辑一致性检查
- 冲突消解(如果不同子Agent的结果有矛盾)
- 最终报告生成
这个步骤很关键。我之前遇到过子Agent返回结果格式不一致,导致父Agent解析失败的情况。所以接口规范一定要提前定义好。
父Agent和子Agent如何交互?
这是多Agent系统的核心问题。
我总结了一个模式:就是让父Agent把子Agent当作工具来调用。
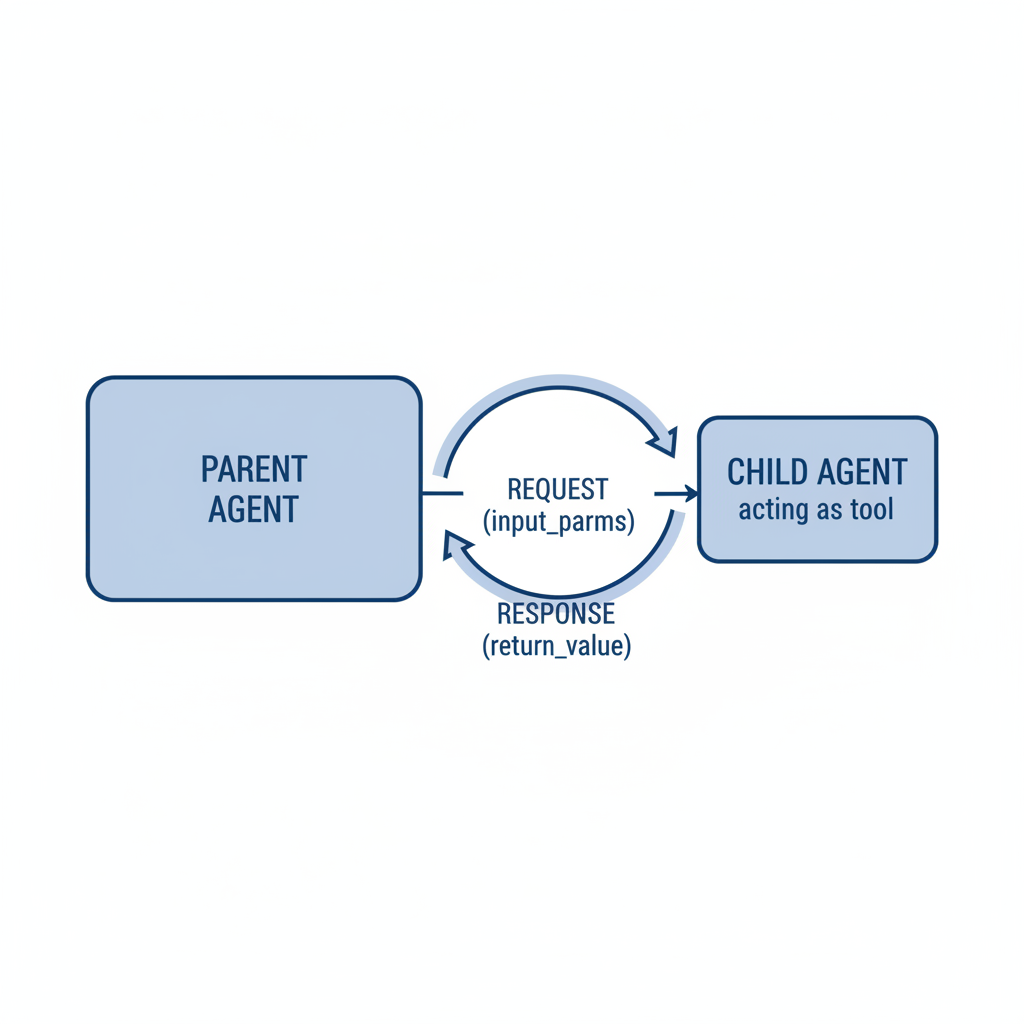
具体的交互流程是这样的:
- 父Agent决定调用子Agent
当父Agent识别到某个任务适合由子Agent处理时,它会发起调用。
比如,父Agent发现需要"调研美国的医疗体系",它会查找注册的子Agent,找到专门负责美国医疗体系的子Agent,然后调用它。
- 父Agent构造调用参数
调用参数以工具入参的形式传递。通常包括:
- 任务描述:明确告诉子Agent要做什么
- 背景信息:任务的整体上下文
- 期望输出:希望子Agent返回什么
举个例子,父Agent可能会这样调用:
调用子Agent "us_healthcare_agent":
{
"task": "调研美国医疗体系的核心特征",
"context": "这是对比五国社会福利体系研究的一部分",
"output_format": "包括医保覆盖率、医疗支出、医疗资源等关键指标"
}
- 子Agent执行任务
子Agent接收到指令后,开始执行自己的任务。它会专注于自己的主题,不受其他信息的干扰。
- 子Agent返回结果
执行完成后,子Agent会把结果返回给父Agent。返回的内容应该是精炼的结论,而不是所有原始数据。
比如,子Agent不会返回"美国2023年医疗支出的所有详细数据",而是返回"美国医疗支出占GDP比重约为18%,是五国中最高的"。
这样做的好处是,可以压缩上下文,减少Token消耗。
- 父Agent处理返回结果
父Agent收到结果后,会做几件事:
- 存储结果
- 检查是否还需要其他信息
- 如果需要,可能再次调用同一个或另一个子Agent
- 最终汇总所有结果,生成最终报告
一个重要的细节:父Agent在调用子Agent时,传入的指令要尽量简洁,只传递必要的信息。
原因有两点:
- 减少子Agent的上下文干扰
- 节省Token成本
我之前犯过一个错误,父Agent把所有背景信息都传给子Agent,结果子Agent的上下文太长,反而影响了效果。
后来学乖了,只传"任务描述+必要的上下文",效果反而更好。
整个智能体应该如何做集成?
聊完了交互细节,接下来说说整体集成。
一个好的多Agent系统,应该具备这几个特性:
- 模块化
每个Agent都是独立的模块,可以单独开发、测试、部署。
这意味着,如果要增加一个新的主题研究,只需要开发一个新的子Agent,注册到父Agent就行,不需要修改整个系统。
- 扩展性
随着业务复杂度增加,系统应该能够:
- 方便地增加新的子Agent
- 调整任务分解的粒度
- 优化调度策略
我建议采用状态机或工作流引擎来管理多Agent的调度。
LangGraph就是个不错的选择。
用LangGraph,你可以把每个Agent定义成一个节点,节点之间的边定义调用关系。整个系统的执行过程,就是在这个图上进行的。
这样做的好处是:
- 可视化强,一眼就能看懂系统架构
- 调试方便,可以追踪每个节点的执行情况
- 扩展容易,增加新节点就行
结语
这个系列写到这里,Deep Research Agent的实战部分就差不多了。
从最初的单Agent架构,到今天的多Agent系统,我们一起探讨了如何构建一个强大的研究型Agent。
回顾这三篇文章,核心思路其实就一个:通过合理的架构设计,让Agent更好地完成任务。
单Agent适合简单场景,多Agent适合复杂的多主题任务。没有绝对的优劣,只有适不适合。
今天我们重点讨论了:
- 父子Agent的交互机制
- 父Agent的Prompt设计
这些内容都是我在实际项目中的经验总结,希望对你有帮助。
接下来,我会写一篇更基础的文章,来拆解什么是Agent的核心。
很多朋友在问我:"Agent到底是个什么?和普通的AI应用有什么区别?"
这篇文章,我会从第一性原理出发,聊聊Agent的本质。
系列文章回顾:
这个系列一共三篇文章,记录了我构建Deep Research Agent的完整实践过程:
- 《Deep Research Agent 实战(一):基础架构》- 从0到1构建研究型Agent
- 《Deep Research Agent 实战(二):实战应用》- 在真实场景中的应用
- 《Deep Research Agent 实战(三):多Agent系统构建》(本篇)- 应对复杂场景的解决方案
如果你对这个主题感兴趣,建议按顺序阅读,会有更完整的理解。
关于作者:
我是代码里程碑,一个AI Native Coder。这个系列文章记录了我构建Deep Research Agent的实践过程。
如果你对Agent系统感兴趣,欢迎在评论区交流。也欢迎关注我的公众号,获取更多AI实战经验。
参考资源:
- Fairy 项目 - 完整的多Agent研究系统
- LangGraph 文档 - 工作流引擎
- LangChain Deep Research - 官方教程