Exploring LLM Agent Evaluation: Understanding the Underlying Logic
In the AI community, LLM evaluation is堪称 a "metaphysical scene": a certain domestic model tops GPT-4 on the C-Eval leaderboard, yet frequently outputs outdated policies in real financial consulting; GPT-4 can pass the bar exam, yet sees its accuracy plummet by 10% on elementary math problems with slightly tweaked numbers. As models evolve from "specialized experts" to "versatile Agents", traditional evaluation systems are experiencing unprecedented disruption.
In traditional evaluation systems, the tasks we perform are standardized, such as image classification, text extraction, sentiment analysis, etc. These tasks have fixed frameworks and standard output results. We can evaluate model performance through metrics like accuracy, recall, F1 score, etc.
However, with the arrival of large language models, model capabilities are no longer standardized but constantly expanding—from AI writing, image generation to AI programming, models can complete a wide variety of tasks. At the same time, the quality of output from these tasks is multi-dimensional and often subjective. This means traditional evaluation systems can no longer meet our needs.
As a bridge connecting technology and scenarios, LLM Agents integrate LLM's understanding, reasoning, and decision-making capabilities and have achieved automated task processing in customer service, healthcare, finance, and other fields. Their evaluation is not only technical verification but also a key risk control step for commercial deployment, directly affecting user experience and business efficiency.
02. What is the Basic Process of LLM Agent Evaluation?
So how should we approach LLM Agent evaluation?
Here's a diagram from the TinyEval project that explains the overall process:
Evaluation Task Flowchart
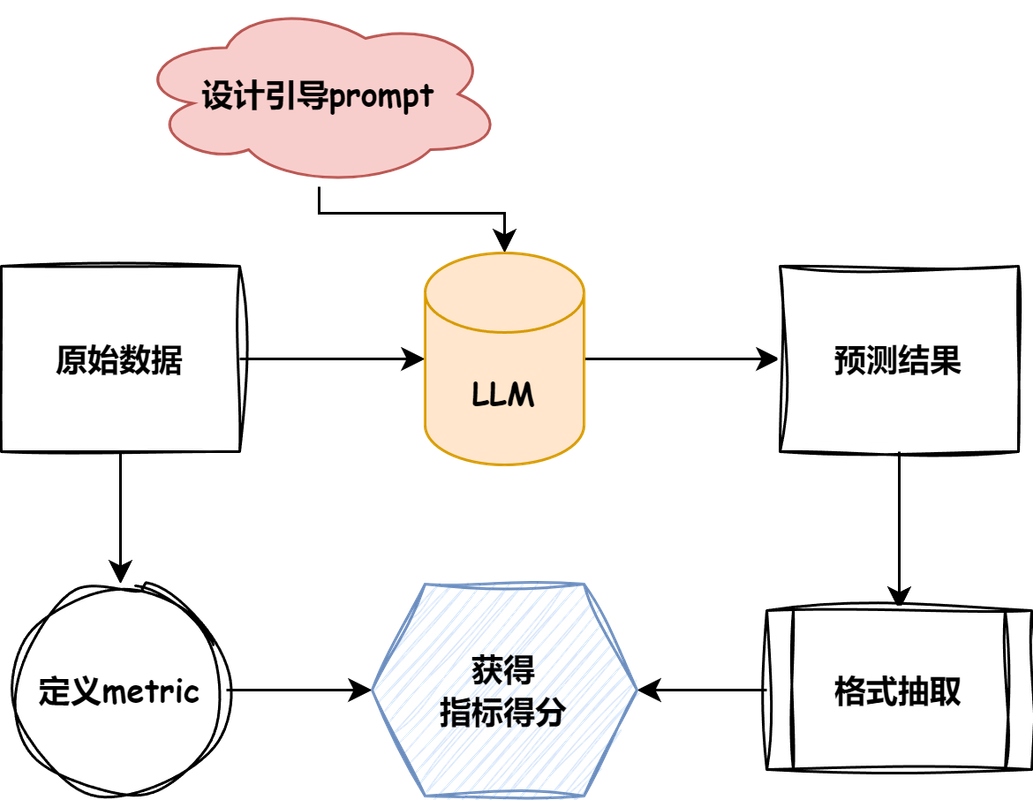
- First, we need to find appropriate datasets and specify suitable evaluation metrics based on the task types in the dataset
- Design guided prompts for the dataset and LLM, and perform inference
- Based on interaction results, design reasonable extraction methods to calculate evaluation results based on the model's inference results and the dataset's expected results
This is the basic process of LLM Agent evaluation.
03. How to Build an Evaluation Process Suitable for Your Business?
How to Choose a Dataset?
If building an Agent for existing business to optimize labor costs, the dataset can be constructed using existing business data, covering as many edge cases as possible to improve the Agent's stability.
But what if you're not facing existing business but a completely new business? How should you construct a dataset?
Let me share some thoughts.
First, explore whether there are existing open-source datasets. If you can find a dataset with aligned objectives, that would naturally be ideal.
If there's no existing dataset, consider whether you can meet your needs by adapting existing datasets.
For example, suppose we plan to build a code review Agent, but there's currently no dedicated dataset for code review.
Currently, most datasets are for code generation. So we can reverse the questions and answers—treating the answers in the dataset as code review questions, and the questions in the dataset as code review answers.
This way, we get a dataset suitable for code review.
How to Choose Metrics?
Metrics mainly depend on answer length, which can be divided into three categories:
| Answer Length Type | Common Evaluation Metrics | Description |
|---|---|---|
| Single/Multiple Choice | Accuracy | Suitable for multiple-choice questions with standard answers, measuring the proportion of predictions matching actual labels |
| Short Text | F1 Score (calculated based on tokenized tokens) | Suitable for short-answer questions, extractive QA, measuring overlap between generated text and reference answers |
| Long Text | BLEU, ROUGE | Suitable for generative QA, writing, etc. BLEU/ROUGE focus on literal overlap |
We can select appropriate metrics based on the dataset type.
How to Design Prompts?
Prompt design mainly depends on the dataset type. Here's an example from TinyEval:
Read the following text and answer briefly in Chinese: {context} Now please answer the following question based on the article above. Only tell me the answer, do not output any other words. Question: {input} Answer:
When designing prompts, we often place the dataset content in the middle of the prompt, then let the model reason based on the prompt.
But there's a problem: if the dataset content is too long, it will cause the model's context length to be insufficient, making it unable to read the content at the end.
Therefore, in the above example, we need to perform truncation on the context to prevent exceeding the model's context length limit.
Summary
Today, we explored the underlying logic of LLM Agent evaluation, covering dataset selection, metric selection, and prompt design.
Next, we will put this into practice and build an evaluation process for a code review LLM Agent.
Hope this helps everyone.
Reference links: