What's Actually Happening When a Model "Thinks"?
More and more models now have a "thinking mode." Some call it thinking, some call it reasoning, and some thinking modes even come with an effort option that lets you tune the intensity from low to high. After turning it on, you can feel the model "thinking" — responses slow down, and sometimes the results really do get more accurate.
But I always had a question: what exactly is it thinking about? What's the difference between this "thinking" and a normal output? More importantly, what's the actual cost of "letting it think a bit more"? And what's the difference between different effort levels?
Recently I ran two sets of tests. One set was local models (Gemma 4 e4b and Qwen 3.5 9b) on a Mac mini M4 inference platform, where I could precisely separate thinking and output token counts. The other set was cloud models (GPT-5.4, GPT-5.5 series, Claude Opus, Sonnet, Haiku), cross-tested across different effort tiers. Over 100 data points in total, and some of the findings were pretty counterintuitive.
1. Inference Speed: The Bottleneck Isn't Input Length
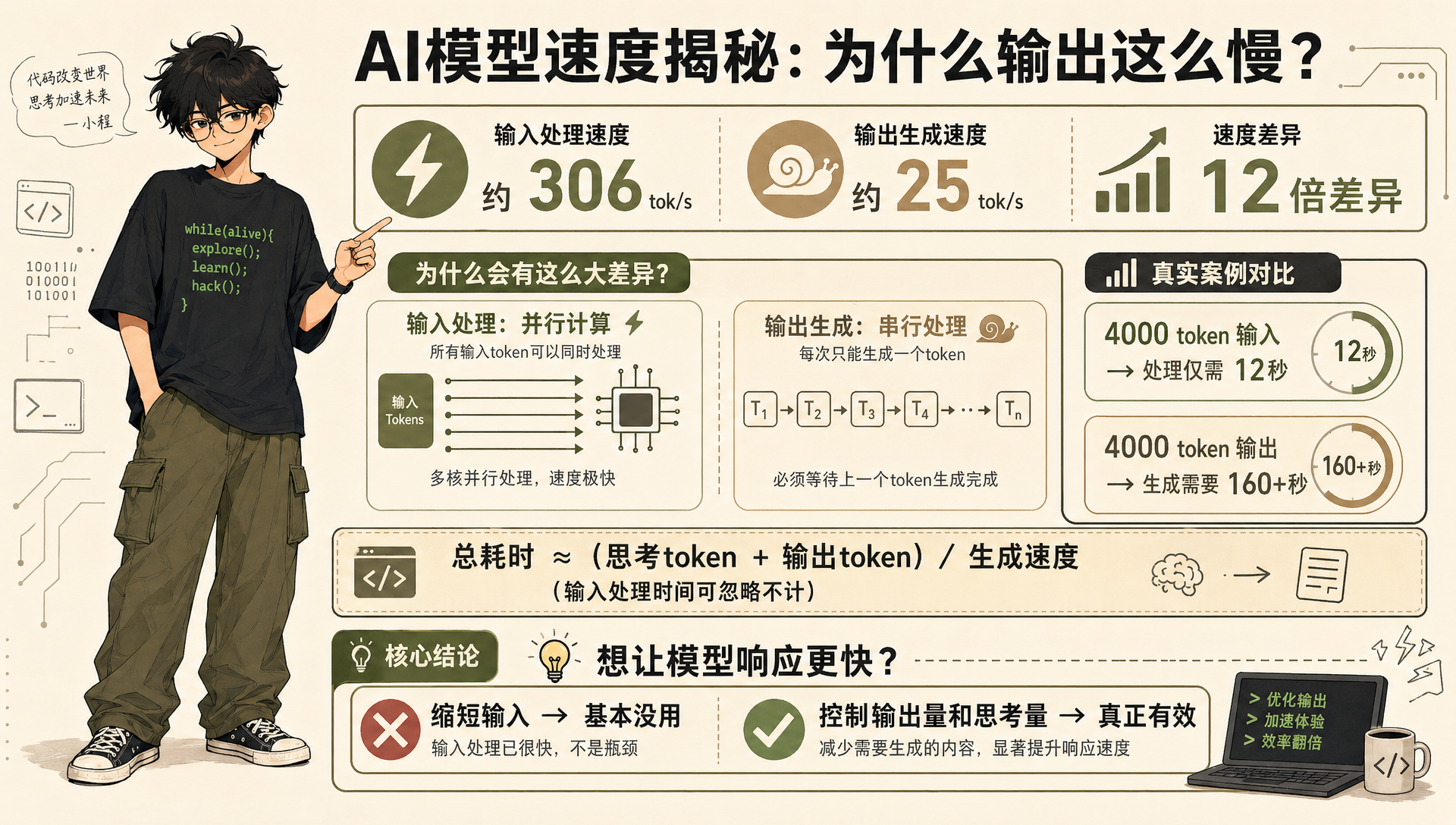
Many people's first intuition is: the longer the input, the slower the model.
But across 85 cross-tests, response time had almost no correlation with input length.
That number surprised me too. After breaking down the time profile of local models, I understood why.
Since local model inference lets you view input token timing and output token timing separately, take Gemma 4 as an example. With thinking off, here's the time breakdown:
| Stage | Percentage |
|---|---|
| Input processing | 3.8% |
| Output generation | 96.2% |
Input processing runs at about 306 tok/s, output generation at about 25 tok/s — a 12x difference. The reason is straightforward: input processing can be parallelized, which is the core reason the Transformer architecture took off, while output generation is serial — it has to spit out one token at a time.
So even feeding in a 4000-token long input only takes 12 seconds to process. But if the model outputs 4000 tokens, that takes over 160 seconds.
Local model timing can be roughly estimated with this formula:
Total time ≈ (thinking tokens + output tokens) / generation speed
The input processing part is basically negligible.
This means: if you want faster model responses, shortening the input is basically useless. What actually helps is controlling the output volume and thinking volume.
2. Thinking Is Just Tokens
Which brings us to a more fundamental question: what exactly are thinking tokens?
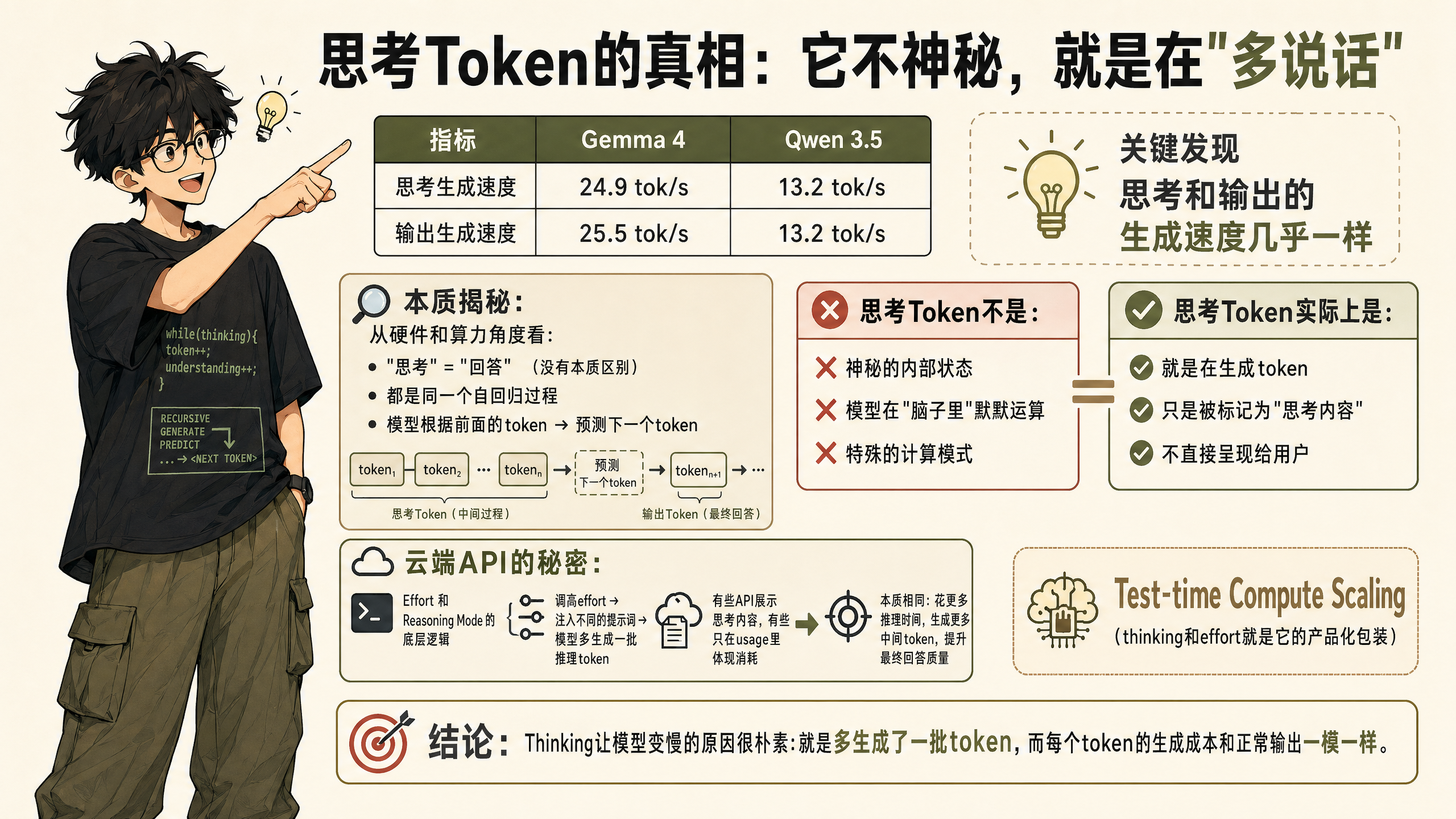
Local models give us a very clean answer. LM Studio splits the inference process into three stages in its returns: input processing, thinking generation, and output generation, with token counts and timing reported separately for each stage.
The most critical set of numbers I saw:
| Metric | Gemma 4 | Qwen 3.5 |
|---|---|---|
| Thinking generation speed | 24.9 tok/s | 13.2 tok/s |
| Output generation speed | 25.5 tok/s | 13.2 tok/s |
Thinking and output generation speeds are nearly identical.
From a hardware and compute perspective, there's no fundamental difference between "thinking" and "answering." They're both the same autoregressive process — the model predicts the next token based on the tokens that came before. Thinking tokens aren't some mysterious internal state, nor are they the model "silently computing in its head." It's just generating tokens, except those tokens are marked as "thinking content" and not shown directly to the user.
The effort and reasoning mode in cloud APIs follow the same underlying logic. Crank up effort, and the system injects different effort prompts, prompting the model to generate an additional batch of reasoning tokens before the final answer. Some APIs show you the thinking content, some only reflect it as extra consumption in usage stats, but the essence is the same: spend more inference time generating more intermediate tokens to improve the quality of the final answer.
There's an academic name for this "trade compute for quality" approach — test-time compute scaling. Thinking and effort are simply how it's been packaged into a productized switch.
So the reason thinking slows down the model is very plain: it just generates an extra batch of tokens, and each token's generation cost is exactly the same as normal output.
3. The Cost of Thinking
Knowing the essence of thinking, the natural next step is to tally up the cost.
First, the good news. After enabling thinking on Gemma 4, an interesting phenomenon emerges: the final output actually gets shorter.
| Input length | Thinking off — output | Thinking on — output | Output change | Thinking tokens | Total time change |
|---|---|---|---|---|---|
| 100 | 1,456 | 1,124 | -23% | 1,072 | +35% |
| 500 | 3,856 | 1,640 | -57% | 2,418 | +5% |
| 2000 | 3,470 | 1,637 | -53% | 2,987 | +28% |
| 4000 | 4,158 | 2,993 | -28% | 2,589 | +29% |
The model "thinks before speaking," and the output becomes more concise. Especially in the 500-token input group: output dropped by 57%, but total time only increased by 5%. The output time saved by thinking almost completely offsets the thinking overhead itself. This is probably one of the sweet spots of thinking mode.
Now the cloud models. With cloud models you can't see the thinking token breakdown — only total time and total output. But the upside is that effort tiers provide a unified "thinking switch" that allows horizontal comparison.
Using 1000-token input as the control variable, first look at Claude's three models (format: time / output tokens):
| Effort | opus | sonnet | haiku |
|---|---|---|---|
| low | 23s / 1,297 | 30s / 1,901 | 18s / 2,125 |
| medium | 23s / 1,447 | 49s / 3,164 | 21s / 2,589 |
| high | 43s / 2,859 | 45s / 3,214 | 40s / 2,941 |
| max | 57s / 3,944 | 202s / 10,718 | 20s / 1,866 |
Opus is the cleanest. From low to max, time goes up 2.5x and output 3x — linear and predictable. Every additional token generated corresponds to a clear time cost.
Sonnet stays stable through the first three tiers, but pushing to max blows everything up: time is 7x that of low, output over 5x. "Max" on Sonnet isn't continuous scaling — it's more like opening a floodgate.
Haiku's behavior is completely unpredictable — max is actually twice as fast as high. On Haiku, effort isn't a knob — it's more like a dice roll. Just how absurd it gets, I'll unpack in the next section.
The GPT family paints a similar picture:
| Effort | gpt-5.4 | gpt-5.5 |
|---|---|---|
| none | 84s / 1,816 | 77s / 1,496 |
| low | 75s / 2,473 | 91s / 2,134 |
| medium | 135s / 3,973 | 126s / 1,775 |
| high | 123s / 5,592 | 145s / 2,386 |
| xhigh | 228s / 8,856 | 202s / 4,003 |
gpt-5.4 from none to xhigh: 2.7x time, 4.9x output, well-behaved. gpt-5.5 at the same tier only sees output grow 2.7x — same label "xhigh," but the two models actually release completely different "thinking budgets."
Combining all the data, the cost pattern for cloud models can be summarized in one sentence:
Higher effort → more output tokens → proportionally more time.
This is consistent with what local models proved earlier: thinking and output share the same generation speed, so additional thinking tokens have to be paid for in time, token by token. Even though cloud models hide the thinking breakdown, time and total output remain highly correlated.
But effort is not a standardized knob. The same labels "max" or "xhigh" mean completely different budget consumption on different models — opus +2.5x, gpt-5.4 +2.7x, sonnet +7x. The gap can be 3x. Switching models means re-baselining; estimating tokens and time based on prior experience often goes badly off.

4. Top-Tier Models Actually Reason Faster
After seeing the cost data above, it's easy to draw a conclusion: just use the cheapest model and crank effort to max, right?
But the data says exactly the opposite.
First look at a number that surprised me — time per output token:
| Model | Time per token |
|---|---|
| opus | 15.0 ms |
| gpt-5.4 | 20.5 ms |
| sonnet | 36.3 ms |
Opus is actually more than twice as fast as Sonnet. That's not the ordering intuition would suggest. But it also shows that you can't "guess" a model's actual inference speed — you have to run it to know.
The more critical difference isn't who's faster per single token, but how different models behave under high effort — totally differently.
Opus cranked to max effort goes from 23 seconds to 57 seconds, 2.5x. The growth is gentle. And its output is extremely stable — output volume and time are almost perfectly linear (R² = 0.978). You can predict when it'll return a result, and you can predict how much content it'll output.
Sonnet is different. At max effort + 1000 token input, time shoots up to 201 seconds, 6.8x that of low effort. And its behavior is unpredictable: some inputs run faster, some blow up completely.
Haiku's problem is more fundamental — effort tiers have nearly lost meaning for it. Look at this raw data:
| Input length | low | medium | high | max |
|---|---|---|---|---|
| 100 | 12.7s | 13.7s | 11.4s | 13.8s |
| 1000 | 17.5s | 20.7s | 40.0s | 19.6s |
| 4000 | 21.1s | 16.9s | 267.4s | 52.0s |
At 1000-token input, max effort (19.6s) is actually twice as fast as high effort (40s). At 4000-token input it's even more absurd: high effort takes 267 seconds — 5x that of max. The reason is that Haiku at high effort easily triggers multi-round tool-calling loops — input tokens balloon from a normal 70K to 310K, and the model isn't thinking about the problem but repeatedly calling tools. Effort is supposed to be a predictable knob, but on Haiku it's more like a dice roll.
I also additionally tested gpt-5.4-mini, which is yet another kind of out-of-control. Under xhigh effort it outputs 7.4x the tokens of the no-reasoning mode, mostly repetitive, low-quality thinking content.
Putting them side by side: opus at max effort processing 1000-token input outputs 3,944 tokens in 57 seconds. Mini at xhigh processing the same input outputs 29,166 tokens in 159 seconds. Mini spent nearly 3x the time, produced 7.4x the tokens, but the effective content is probably less than Opus's.
This leads to completely different recommendations for different scenarios.
If you're a user of coding tools — using products like Claude Code, Cursor, or Codex — just pick the top-tier model directly. It not only has the highest quality, but in actual use it's often the fastest too. Because top-tier models don't lose control under high effort: every thinking token is doing useful reasoning, not mindlessly piling on volume. Opus spending 57 seconds to give you a stable result is way more worth it than Sonnet spending 202 seconds to give you an uncertain one.
If you're an API developer billing per token, you have to do the total accounting. Small model unit prices are indeed cheap, but if it outputs 29K tokens at high effort while the large model outputs only 3.4K, your total spending might actually be higher with the small model. Not to mention most of those 29K tokens are filler — you still have to do extra filtering or retries. Sometimes running a big model at medium effort beats a cheap model at max effort, both in total cost and quality.
Closing
Back to the original question: what's actually happening when a model "thinks"?
The answer is plainer than imagined. It's generating tokens. Exactly the same tokens as output, same speed, same cost — just marked as thinking content. Thinking isn't a free enhancement, but an on-demand reasoning budget — you choose how long to wait and how many tokens to spend in exchange for a higher-quality answer.
As for which model to choose and how high to set effort, you can't go by intuition. Same word "thinking," but every Opus token is genuinely reasoning, while Mini might just be talking to itself. That kind of difference is only visible after real testing.