当模型"思考"时,到底在发生什么?
现在越来越多模型都有了"思考模式"。有的叫 thinking,有的叫 reasoning,有些思考模式还具备了 effort 选项,可以调整思考力度,可以从低到高进行选择。打开之后,确实能感觉到模型"在想"——响应变慢了,有时候结果也确实更准了。
但我一直有个疑问:它到底在想什么?这个"想"和正常输出有什么区别?更关键的是,每次"让它多想一会儿"到底要付出什么代价?不同的 effort 之间又有什么不同?
最近我跑了两组测试。一组是本地模型(Gemma 4 e4b 和 Qwen 3.5 9b), 推理平台是 mac mini m4,可以精确拆分思考和输出的 token 数量;另一组是云端模型(GPT-5.4、GPT-5.5系列、Claude Opus、Sonnet、haiku),通过不同 effort 档位做交叉测试。总共 100 多组数据跑下来,有些发现挺反直觉的。
1. 推理速度:瓶颈不在输入长度
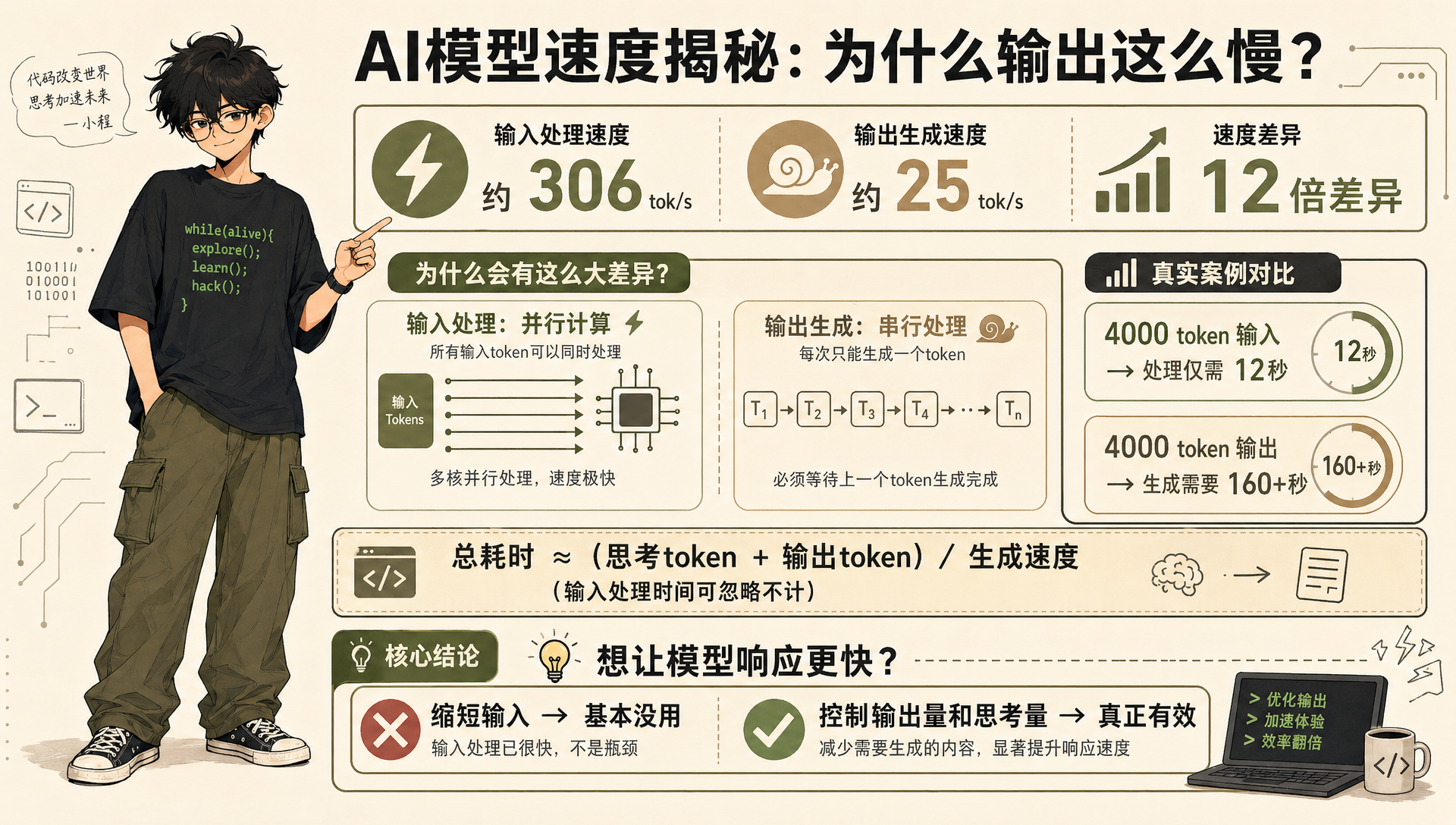
很多人的第一直觉是:输入越长,模型越慢。
但 85 组交叉测试跑下来,耗时和输入长度几乎完全无关。
这个数字让我也有点意外。拆开本地模型的耗时结构之后,才理解了原因。
由于本地模型推理可以分别查看输入 Token 耗时和输出 Token 耗时,以 Gemma 4 为例,不开思考时的耗时占比:
| 阶段 | 占比 |
|---|---|
| 输入处理 | 3.8% |
| 输出生成 | 96.2% |
输入处理速度大约 306 tok/s,输出生成速度大约 25 tok/s,差了 12 倍。原因很直接:输入处理可以并行计算,这也是 Transformer 架构得以流行的核心原因,而输出生成是串行的——必须一个 token 一个 token 地往外吐。
所以即使喂进去 4000 token 的长输入,处理时间也不过 12 秒。但模型如果输出 4000 token,就得花 160 多秒。
本地模型的耗时可以粗略用这个公式估算:
总耗时 ≈ (思考 token + 输出 token) / 生成速度
输入处理那部分,基本可以忽略不计。
这意味着:想让模型响应更快,缩短输入基本没用。真正有用的是控制输出量和思考量。
2. 思考就是 token
说到这里,一个更根本的问题浮出来了:思考 token 到底是什么?
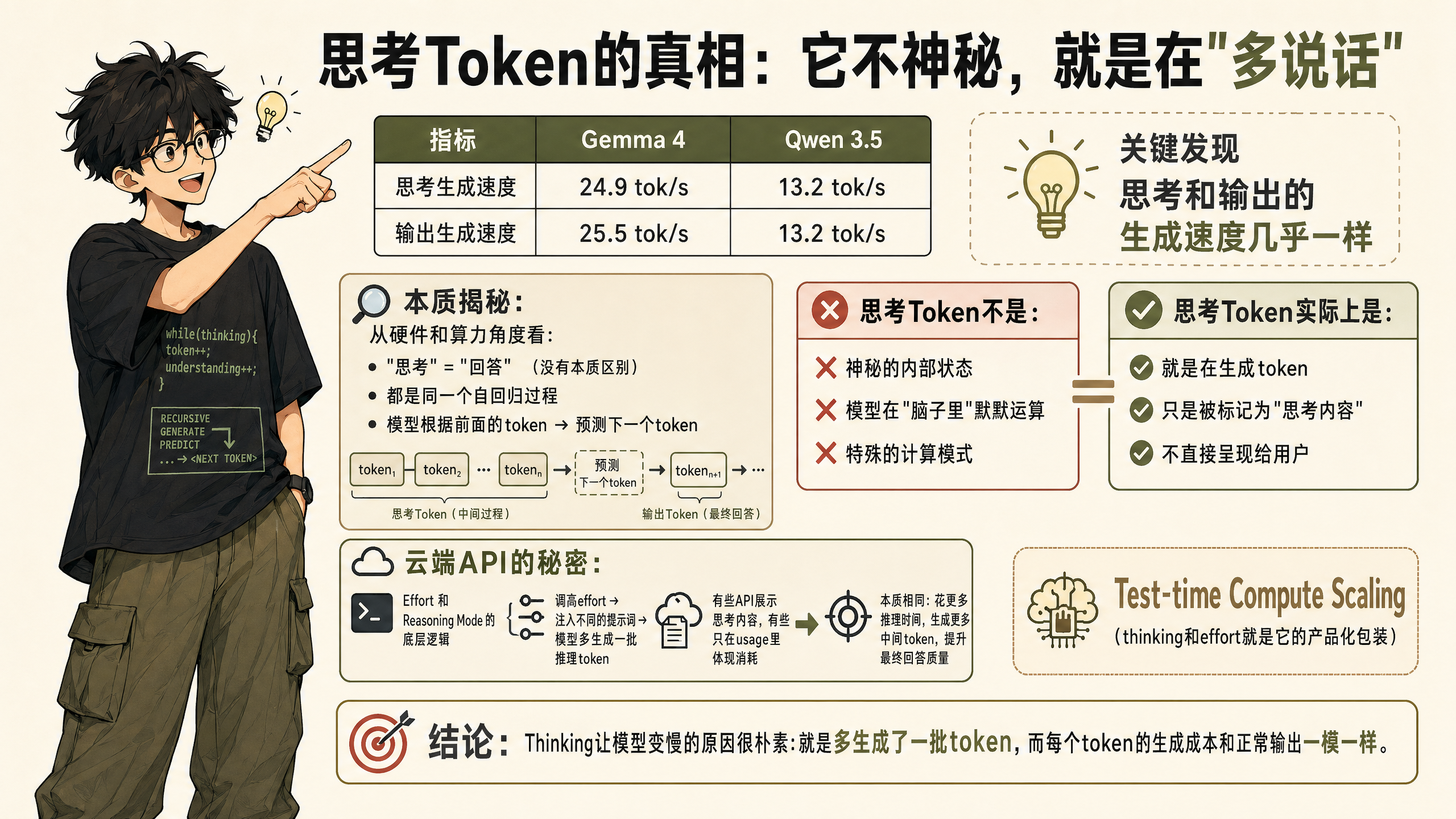
本地模型给了一个非常干净的答案。LM Studio 会把推理过程拆成三个阶段返回:输入处理、思考生成、输出生成,每个阶段的 token 数和耗时都分开报告。
我看到的最关键的一组数字:
| 指标 | Gemma 4 | Qwen 3.5 |
|---|---|---|
| 思考生成速度 | 24.9 tok/s | 13.2 tok/s |
| 输出生成速度 | 25.5 tok/s | 13.2 tok/s |
思考和输出的生成速度几乎一样。
从硬件和算力的角度看,"思考"和"回答"没有任何本质区别。它们都是同一个自回归过程——模型根据前面已有的 token,预测下一个 token。思考 token 不是什么神秘的内部状态,不是"模型在脑子里默默运算"。它就是在生成 token,只不过这些 token 被标记为"思考内容",不直接呈现给用户。
云端 API 里的 effort 和 reasoning mode,底层逻辑也是这件事。调高 effort,系统会注入不同的 effort 提示词,模型就在最终回答之前多生成一批推理 token。有些 API 会把思考内容展示给你,有些只在 usage 里体现为额外消耗,但本质一样:花更多的推理时间,生成更多的中间 token,来提升最终回答的质量。
这种"多花算力换质量"的做法有个学术名字,叫 test-time compute scaling。thinking 和 effort,就是把它包装成了一个产品化的开关。
所以 thinking 让模型变慢的原因非常朴素:它就是多生成了一批 token,而每个 token 的生成成本和正常输出一模一样。
3. 思考的成本
知道了思考的本质,下一步自然是算账。
先看好的一面。Gemma 4 开启思考后,一个有意思的现象是:最终输出反而变短了。
| 输入长度 | 关闭思考-输出 | 开启思考-输出 | 输出变化 | 思考 token | 总耗时变化 |
|---|---|---|---|---|---|
| 100 | 1,456 | 1,124 | -23% | 1,072 | +35% |
| 500 | 3,856 | 1,640 | -57% | 2,418 | +5% |
| 2000 | 3,470 | 1,637 | -53% | 2,987 | +28% |
| 4000 | 4,158 | 2,993 | -28% | 2,589 | +29% |
模型"先想后说",输出更精炼了。特别是 500 token 输入那组:输出量降了 57%,但总耗时只增加了 5%。思考节省的输出时间,几乎完全抵消了思考本身的开销。这大概是思考模式的一个甜蜜点。
再看云端模型。云端看不到思考 token 的明细,只能看总耗时和总 output。但好处是 effort 档位提供了一个统一的"思考开关",可以横向对比。
用 1000 token 输入做控制变量,先看 Claude 三个模型(数字格式:耗时 / output token):
| Effort | opus | sonnet | haiku |
|---|---|---|---|
| low | 23s / 1,297 | 30s / 1,901 | 18s / 2,125 |
| medium | 23s / 1,447 | 49s / 3,164 | 21s / 2,589 |
| high | 43s / 2,859 | 45s / 3,214 | 40s / 2,941 |
| max | 57s / 3,944 | 202s / 10,718 | 20s / 1,866 |
opus 最干净。从 low 到 max,耗时 2.5 倍、output 3 倍,线性、可预测。每多生成的 token 都对应明确的时间代价。
sonnet 前三档都还稳,但加到 max 直接炸开:耗时是 low 的 7 倍,output 5 倍多。"max" 在 sonnet 上不是连续加码,更像打开闸门。
haiku 的表现完全不可预测——max 比 high 反而快一倍,effort 在它身上已经不是旋钮,更像骰子。具体有多离谱,下一节展开。
GPT 系列的图景也类似:
| Effort | gpt-5.4 | gpt-5.5 |
|---|---|---|
| none | 84s / 1,816 | 77s / 1,496 |
| low | 75s / 2,473 | 91s / 2,134 |
| medium | 135s / 3,973 | 126s / 1,775 |
| high | 123s / 5,592 | 145s / 2,386 |
| xhigh | 228s / 8,856 | 202s / 4,003 |
gpt-5.4 从 none 到 xhigh,耗时 2.7 倍、output 4.9 倍,行为规矩。gpt-5.5 同样档位 output 只涨 2.7 倍——同名的 "xhigh",两个模型实际放出的"思考预算"完全不一样。
把所有数据合起来,云端模型的成本规律可以归纳成一句:
effort 调高 → output token 增加 → 耗时同步增加。
这跟前面本地模型证明的事实是一致的:思考和输出共享同一档生成速度,多生成的思考 token 必须按 token 数付时间。云端虽然看不到思考明细,耗时和总 output 同样高度正相关。
但 effort 不是一个标准化的旋钮。同样标签的 "max" 或 "xhigh",在每个模型上意味着完全不同的预算消耗——opus +2.5 倍、gpt-5.4 +2.7 倍、sonnet +7 倍。差距能到 3 倍。换模型就得重新摸底,按之前的经验估算 token 和耗时往往严重失真。

4. 顶级模型推理反而更快
看完上面的思考成本数据,很容易得出一个结论:那我就用最便宜的模型,effort 开到最高不就行了?
但数据说的恰好相反。
先看一个让我意外的数字——每个 output token 的生成耗时:
| 模型 | 每 token 耗时 |
|---|---|
| opus | 15.0 ms |
| gpt-5.4 | 20.5 ms |
| sonnet | 36.3 ms |
opus 居然比 sonnet 快了一倍多。这不是直觉上该有的排序。但这也说明,模型的实际推理速度不是靠"猜"能猜对的,得实际跑了才知道。
更关键的区别,不在于谁单个 token 更快,而在于不同模型面对高 effort 时的行为完全不同。
opus 加到 max effort,耗时从 23 秒涨到 57 秒,2.5 倍。增长很温和。而且它的产出极其稳定——输出量和耗时几乎完美线性(R² = 0.978)。你能预测它什么时候返回结果,也能预测它会输出多少内容。
sonnet 就不一样了。在 max effort + 1000 token 输入下,耗时直接飙到 201 秒,是 low effort 时的 6.8 倍。而且行为不可预测:有些输入下反而更快,有些输入下直接炸掉。
haiku 的问题更根本——effort 档位对它几乎失去了含义。看这组原始数据:
| 输入长度 | low | medium | high | max |
|---|---|---|---|---|
| 100 | 12.7s | 13.7s | 11.4s | 13.8s |
| 1000 | 17.5s | 20.7s | 40.0s | 19.6s |
| 4000 | 21.1s | 16.9s | 267.4s | 52.0s |
1000 token 输入下,max effort(19.6 秒)居然比 high effort(40 秒)快一倍。4000 token 输入下更离谱:high effort 耗时 267 秒,是 max 的 5 倍。原因是 haiku 在高 effort 下容易触发多轮工具调用循环——输入 token 从正常的 7 万暴涨到 31 万,模型不是在思考问题,而是在反复调工具。effort 本该是一个可预测的旋钮,但在 haiku 上更像一个骰子。
我还额外测了 gpt-5.4-mini,又是另一种失控。xhigh effort 下输出的 token 是无推理模式的 7.4 倍,大部分是重复的低质量思考内容。
把它们放在一起看:opus 在 max effort 下处理 1000 token 输入,输出 3,944 token,耗时 57 秒。mini 在 xhigh 下处理同样的输入,输出 29,166 token,耗时 159 秒。mini 花了近 3 倍时间,产出了 7.4 倍的 token,但有效内容可能还不如 opus。
这对不同场景的选择建议完全不同。
如果你是编码工具的用户——用 Claude Code、Cursor、Codex 这类产品——直接选最顶级的模型。它不但质量最高,实际使用中往往反而最快。因为顶级模型在高 effort 下不会失控,每个思考 token 都在做有用的推理,不会无脑堆量。opus 花 57 秒给你一个稳定结果,比 sonnet 花 202 秒给你一个不确定的结果,划算太多。
如果你是 API 开发者,按 token 计费,那要算总账。小模型单价确实便宜,但如果它在高 effort 下输出 29k token,而大模型只输出 3.4k token,总花费可能反而是小模型更贵。更不用说那 29k token 里大部分是废话,你还得额外做过滤或者重试。有时候用贵模型跑中等 effort,比用便宜模型跑满 effort,总成本更低、质量更好。
结语
回到最初的问题:当模型"思考"时,到底在发生什么?
答案比想象中朴素。它在生成 token。和输出一模一样的 token,速度一样,成本一样,只是被标记为思考内容。thinking 不是免费增强,而是一种按需购买的推理预算——你愿意多等多久、多花多少 token,来换一个更高质量的回答。
至于选哪个模型、开多高的 effort,不能靠直觉。同样是"思考",opus 的每个 token 都在认真推理,mini 可能只是在自言自语。这种差异,只有实测了才看得到。