Deep Research Agent 实战(二):基础研究型Agent构建
嘿,朋友们,欢迎回到我们的 "Deep Research Agent" 实战系列!
在上一篇文章中,我们探讨了 Research Agent 的核心理念。今天,我们要动真格的了——卷起袖子,一步步构建一个属于我们自己的基础研究型 Agent!
迭代一款产品总是令人兴奋的,不是吗?这次,我们不仅会深入两大核心工作流的内部构造,还会将最终的成果封装成一个包含前后端的服务。
所有代码均已在我们的开源项目 Fairy 中同步更新,欢迎大家随时取用和改造:
https://github.com/codemilestones/Fairy
准备好了吗?让我们先从最终的 Demo 效果看起,然后一头扎进构建的细节里去吧!
Research Agent Demo
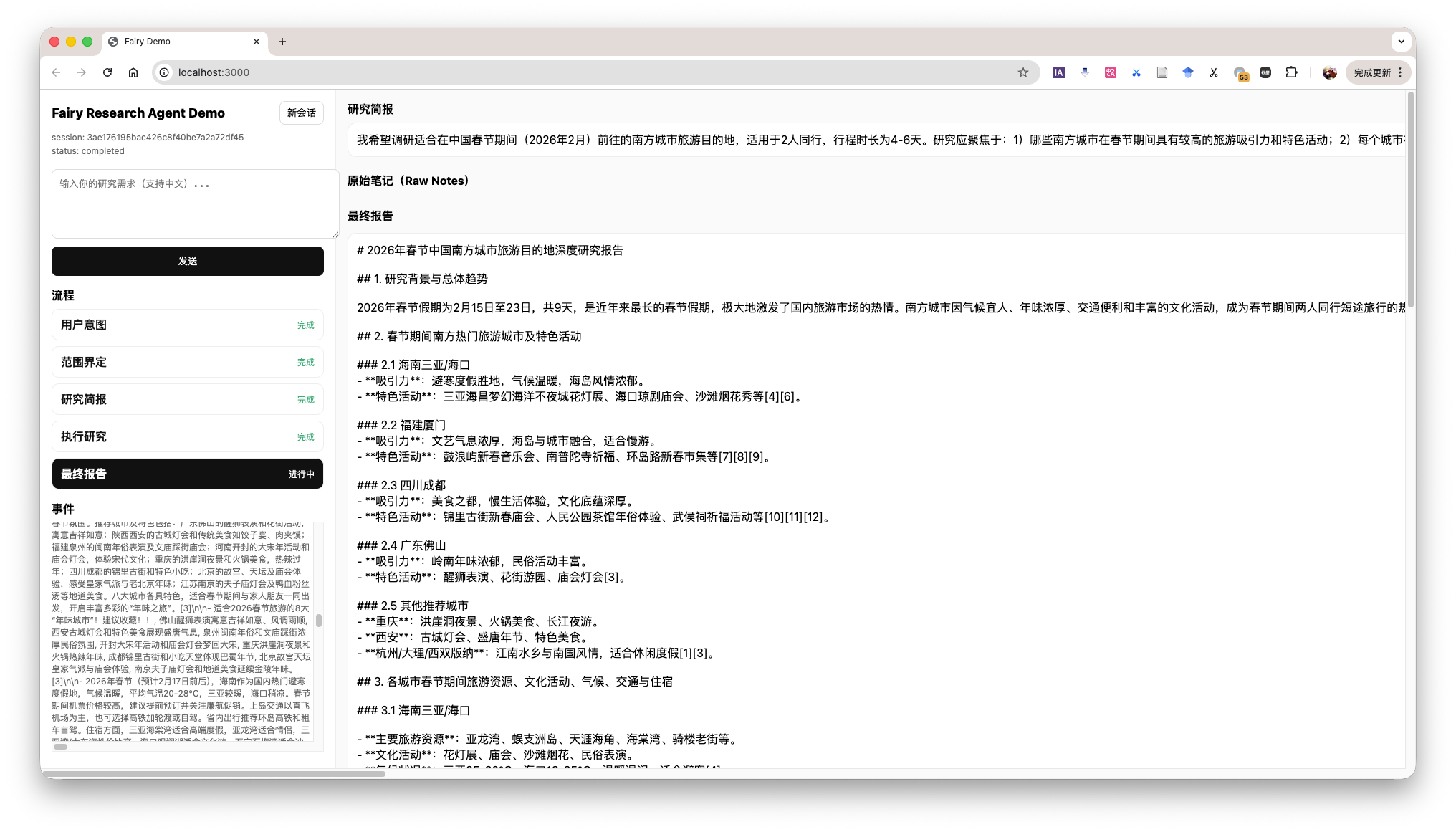
在 demo 中,展示了 Agent 整体的运行流程,同时也在左下角展示当前的上下文,和 Agent 看到的内容是相同的,有助于我们理解 Agent 的运行过程。
阶段一:研究范围界定
万事开头难,研究的第一步就是搞清楚“到底要研究什么”。如果需求模糊,后续的工作很可能全盘白费。因此,我们的第一个 Agent 就像一个严谨的需求分析师。
它的核心目标是:通过与用户持续对话,直到用户的研究需求被完全明确为止。
这个阶段的核心是构建一个 LangGraph 运行图,它主要包含两个关键节点:clarify_with_user(与用户澄清)和 write_research_brief(生成研究简报)。
- 输入:用户的原始研究需求。
- 处理:LLM 判断信息是否完备。如果不完备,生成澄清问题;如果完备,则进入下一步。
- 输出:一份结构化的研究问题(Research Brief),包含研究主题、目标受众、关键问题列表等。
整体的 LangGraph 运行图如下所示:
研究范围界定流程
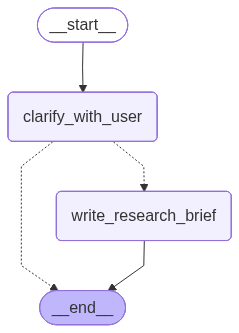
具体的调用流程就是用户的对话信息是全局的,Agent都能看到,然后每次都会调用这个图,Agent会选择继续澄清,还是生成研究背景简报。
这个阶段涉及了两个节点(clarify_with_user 和 write_research_brief),所以我们需要写两个节点的提示词。
下面是 clarify_with_user 节点的提示词,它赋予了 Agent 做选择判断的能力。为了便于大家学习,教程中的英文提示词我都翻译成了中文。
这些是迄今为止从要求报告的用户那里交换的消息:
<Messages>
{messages}
</Messages>
今天的日期是 {date}。
评估你是否需要提出澄清问题,或者用户是否已经提供了足够的信息让你开始研究。
重要提示:如果你能在消息历史中看到你已经提出了澄清问题,你不需要再提出另一个问题。只有绝对必要时才提出另一个问题。
如果有首字母缩写词、缩写或未知术语,请让用户澄清。
如果您需要提问,请遵循以下步骤:
- 简洁明了地收集所有必要信息
- 确保以简洁、结构良好的方式收集完成研究任务所需的所有信息。
- 如有必要,使用项目符号或编号列表以提高清晰度。请确保使用了 Markdown 格式,并且如果将字符串输出传递给 Markdown 渲染器,能够正确呈现。
- 不要询问不必要的信息,或者用户已经提供的信息。如果您看到用户已经提供了信息,请不要再次询问。
使用这些精确的键以有效的JSON格式响应:
"need_clarification": boolean,
"question": "<要求用户澄清报告范围的问题>",
"verification": "<我们将开始研究的已验证信息>"
如果你需要问一个澄清性的问题, 返回如下:
"need_clarification": true,
"question": "<你的澄清问题>",
"verification": ""
如果你不需要问一个澄清性的问题,返回如下:
"need_clarification": false,
"question": "",
"verification": "<你将开始研究所基于的确切信息>"
对于不需要澄清的验证信息:
- 确认你有足够的信息可以继续
- 简要总结你从他们的请求中了解到的关键方面
- 确认你现在将开始研究过程
- 保持信息的简洁和专业
当 Agent 确认所有信息都已到位后,就会调用 write_research_brief 节点,根据下面的提示词,生成一份详尽的 研究问题简报。
你将收到一组迄今为止在你和用户之间交换的消息。
你的工作是将这些消息转化为更详细和具体的研究问题,该问题将用于指导研究。
迄今为止在你和用户之间交换的消息是:
<Messages>
{messages}
</Messages>
今天的日期是 {date}。
你将返回一个用于指导研究的研究问题。
指南:
1. 最大化具体性和细节
- 包含所有已知的用户偏好,并明确列出要考虑的关键属性或维度。
- 重要的是,用户的所有细节都必须包含在说明中。
2. 谨慎处理未声明的维度
- 当研究质量需要考虑用户未指定的其他维度时,将它们确认为开放性考虑因素,而不是假设的偏好。
- 例如: 不要假设"经济实惠的选择",而应说"考虑所有价格范围,除非指定了成本限制。"
- 仅提及在该领域进行全面研究真正必要的维度。
3. 避免不必要的假设
- 永远不要编造用户未声明的特定偏好、约束或要求。
- 如果用户没有提供特定的细节,请明确说明这种缺失。
- 指导研究人员将未指定的方面视为灵活的,而不是做出假设。
4. 区分研究范围和用户偏好
- 研究范围: 应该调查哪些主题/维度(可以比用户明确提及的更广泛)
- 用户偏好: 特定的约束、要求或偏好(必须仅包含用户声明的内容)
- 例如: "研究旧金山咖啡店的咖啡质量因素(包括豆类采购、烘焙方法、冲泡技术),主要关注用户指定的口味。"
5. 使用第一人称
- 从用户的角度表述请求。
6. 来源
- 如果应该优先考虑特定来源,请在研究问题中指定它们。
- 对于产品和旅游研究,优先链接到官方或主要网站(例如,官方品牌网站、制造商页面或信誉良好的电子商务平台如Amazon用于用户评论),而不是聚合网站或SEO密集型博客。
- 对于学术或科学查询,优先链接到原始论文或官方期刊出版物,而不是综述论文或二手摘要。
- 对于人物,尝试直接链接到他们的LinkedIn个人资料,或如果他们有个人网站的话。
- 如果查询是特定语言,优先考虑以该语言发布的来源。
阶段二:执行研究和报告撰写
有了清晰的 研究问题简报 作为“作战地图”,我们的第二个 Agent——“研究执行官”——就可以登场了。
它的目标是:根据研究简报,高效地执行信息搜集,并最终撰写出一份结构化的研究报告。
这个阶段的运行图更为复杂,包含了 llm_call_node(LLM 决策节点)、tool_node(工具调用节点)和 compress_research(研究报告生成)。
- 输入:用户的研究问题。
- 处理:LLM 循环决策:是信息足够可以写报告了,还是需要调用工具进行新一轮搜索?
- 输出:一份详尽的 研究报告 (Research Report)。
整体的 LangGraph 运行图如下所示:
执行研究和报告撰写流程
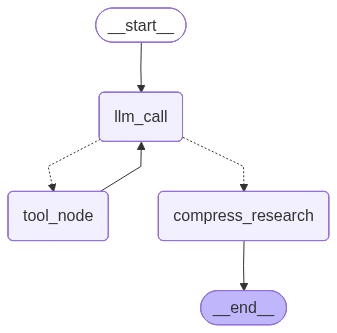
具体的调用流程就是用户的研究问题会传递给 llm_call_node 节点,然后该节点会调用 LLM 进行决策,如果决策结果是需要更多信息,则调用 tool_node 节点进行搜索,如果决策结果是可以结束研究,则调用 compress_research 节点进行研究报告生成。
对于外部视角来看,只要进入了问题研究阶段,就会一直循环下去,直到研究报告生成完成。用户也无法干预这个过程。
这个阶段涉及了三个节点(llm_call_node、tool_node 和 compress_research),我们需要写两个节点的提示词,一个是 llm_call_node 的提示词,一个是 compress_research 的提示词。
一旦进入这个阶段,Agent 就会在一个循环中不断工作,直到产出最终报告,用户无法中途干预。
我们为 Agent 配备了两大神器 🛠️:tavily_search 用于网络搜索,think_tool 用于在搜索后进行反思和规划。
研究阶段最重要的问题是:要控制研究链路的停止,太早或太晚都不好。
因此 llm_call_node 的提示词明确了如何使用这些工具,并设定了停止条件,防止无限循环。
下面是 llm_call_node 的提示词,该提示词会判断当前的信息是否足够,如果不够,则生成搜索关键词。
你是一个研究助手,正在对用户的输入主题进行研究。作为背景,今天的日期是 {date}。
<Task>
你的工作是使用工具收集有关用户输入主题的信息。
你可以使用提供给你的任何工具来查找可以帮助回答研究问题的资源。你可以串行或并行调用这些工具,你的研究是在工具调用循环中进行的。
</Task>
<Available Tools>
你可以访问两个主要工具:
1. **tavily_search**: 用于进行网络搜索以收集信息
2. **think_tool**: 用于研究期间的反思和战略规划
**关键: 在每次搜索后使用 think_tool 来反思结果并规划下一步**
</Available Tools>
<Instructions>
像一个时间有限的人类研究员一样思考。按照以下步骤:
1. **仔细阅读问题** - 用户需要什么具体信息?
2. **从更广泛的搜索开始** - 首先使用广泛、全面的查询
3. **每次搜索后暂停并评估** - 我有足够的答案吗? 还缺少什么?
4. **随着收集信息执行更窄的搜索** - 填补空白
5. **当你可以自信地回答时停止** - 不要继续搜索以追求完美
</Instructions>
<Hard Limits>
**工具调用预算** (防止过度搜索):
- **简单查询**: 最多使用 2-3 次搜索工具调用
- **复杂查询**: 最多使用 5 次搜索工具调用
- **始终停止**: 如果在 5 次搜索工具调用后无法找到正确的来源
**立即停止当**:
- 你可以全面回答用户的问题
- 你有 3 个以上与问题相关的示例/来源
- 你最后 2 次搜索返回了类似的信息
</Hard Limits>
<Show Your Thinking>
在每次搜索工具调用后,使用 think_tool 来分析结果:
- 我找到了什么关键信息?
- 缺少什么?
- 我有足够的信息来全面回答问题吗?
- 我应该继续搜索还是提供我的答案?
</Show Your Thinking>
当 Agent 收集到足够的信息后,compress_research 节点会被调用。它的 Prompt 指导 LLM 如何将零散的网页内容,总结成结构化、信息丰富的摘要,并提供了几个高质量的示例。
示例可以按照我们希望的风格来进行放置,这部分的内容可以根据实际需求进行调整。
你的任务是总结从网络搜索中检索到的网页的原始内容。你的目标是创建一个保留原始网页最重要信息的摘要。此摘要将被下游研究代理使用,因此保持关键细节而不丢失重要信息至关重要。
以下是网页的原始内容:
<webpage_content>
{webpage_content}
</webpage_content>
请遵循以下准则创建你的摘要:
1. 识别并保留网页的主要主题或目的。
2. 保留对内容信息至关重要的关键事实、统计数据和数据点。
3. 保留来自可靠来源或专家的重要引用。
4. 如果内容具有时间敏感性或历史性,请保持事件的时间顺序。
5. 如果存在,保留任何列表或分步说明。
6. 包括对理解内容至关重要的相关日期、名称和地点。
7. 总结冗长的解释,同时保持核心信息完整。
处理不同类型的内容时:
- 对于新闻文章: 关注谁、什么、何时、何地、为什么和如何。
- 对于科学内容: 保留方法论、结果和结论。
- 对于观点文章: 保持主要论点和支持要点。
- 对于产品页面: 保留关键功能、规格和独特卖点。
你的摘要应该比原始内容短得多,但要足够全面,可以作为独立的信息来源。目标是原始长度的约 25-30%,除非内容已经很简洁。
以以下格式呈现你的摘要:
{{
"summary": "你的摘要在这里,根据需要使用适当的段落或项目符号进行结构化",
"key_excerpts": "第一个重要的引用或摘录,第二个重要的引用或摘录,第三个重要的引用或摘录,...根据需要添加更多摘录,最多 5 个"
}}
以下是两个良好摘要的示例:
示例 1 (新闻文章):
json
{{
"summary": "2023年7月15日,NASA从肯尼迪航天中心成功发射了Artemis II任务。这标志着自1972年Apollo 17以来的第一次载人登月任务。由指挥官Jane Smith领导的四人团队将在返回地球前绕月球运行10天。这项任务是NASA计划到2030年在月球上建立永久人类存在的关键步骤。",
"key_excerpts": "Artemis II代表着太空探索的新时代,NASA局长John Doe说。该任务将测试未来在月球上长期停留的关键系统,首席工程师Sarah Johnson解释道。我们不仅仅是回到月球,我们是向前进入月球,指挥官Jane Smith在发射前新闻发布会上表示。"
}}
示例 2 (科学文章):
json
{{
"summary": "发表在《自然气候变化》上的一项新研究表明,全球海平面上升的速度比以前认为的要快。研究人员分析了1993年至2022年的卫星数据,发现在过去三十年中,海平面上升的速度加速了0.08毫米/年²。这种加速主要归因于格陵兰和南极洲冰盖的融化。研究预测,如果当前趋势继续下去,到2100年,全球海平面可能上升多达2米,对全球沿海社区构成重大风险。",
"key_excerpts": "我们的发现表明海平面上升明显加速,这对沿海规划和适应策略具有重大意义,主要作者Emily Brown博士表示。研究报告称,格陵兰和南极洲的冰盖融化速度自1990年代以来增加了三倍。如果不立即大幅减少温室气体排放,到本世纪末我们将面临潜在的灾难性海平面上升,合著者Michael Green教授警告道。"
}}
记住,你的目标是创建一个易于理解并可被下游研究代理使用的摘要,同时保留原始网页的最关键信息。
今天的日期是 {date}。
流程整合:打造端到端的研究助理
OK,经过上面两部分的构建,我们现在已经拥有了两个独立的“专家” Agent:一个擅长“界定范围”,另一个精于“执行研究”。
接下来,最激动人心的部分来了——我们要如何将它们整合起来,打造一个端到端的自动化研究流程呢?让我们看看最终的“合体”运行图!
研究 Agent 流程
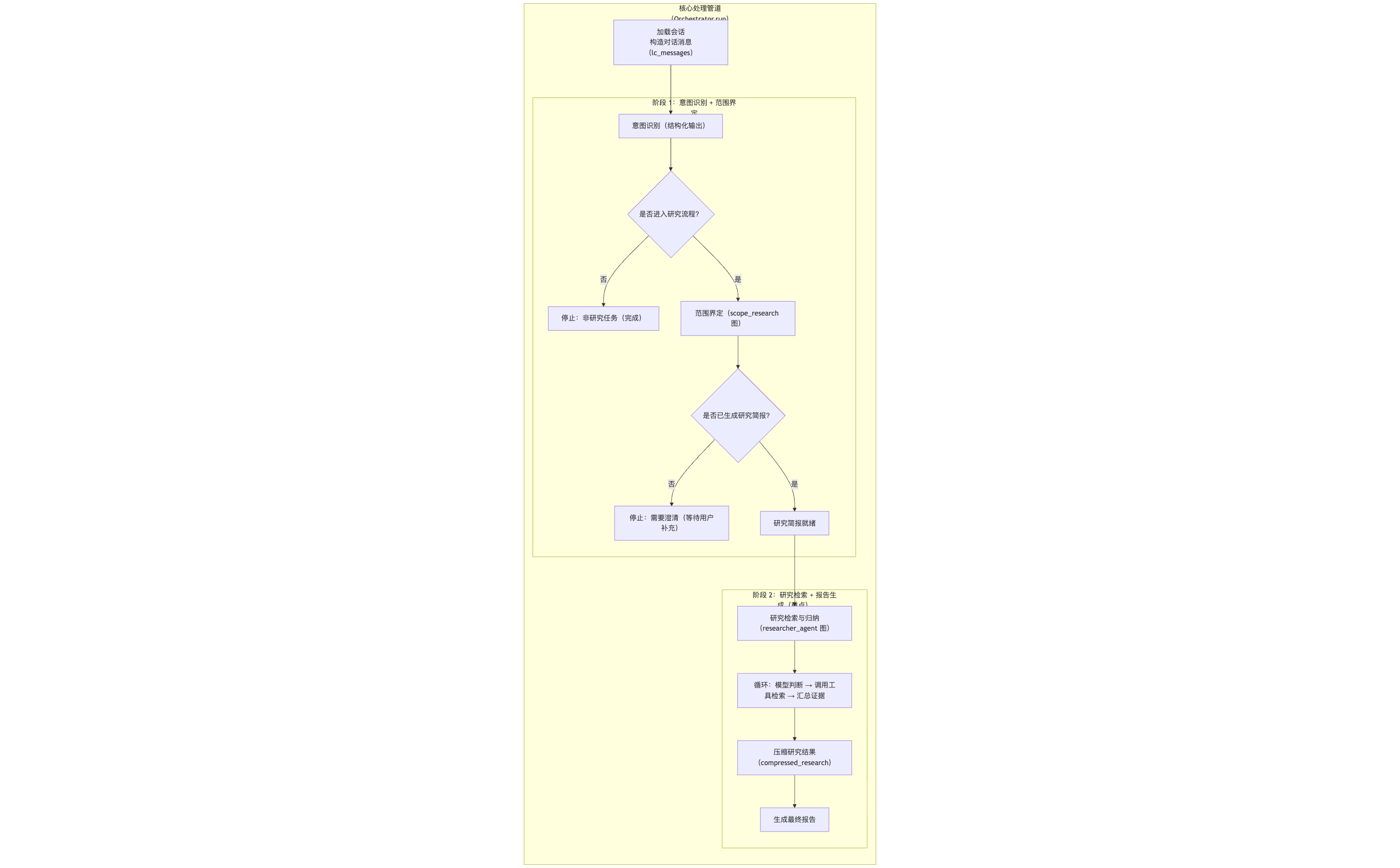
如上图所示,整个流程被清晰地划分为两个阶段,串行执行。用户输入研究需求后,首先进入阶段一,一旦生成了 研究简报,流程就自动进入阶段二,并在该阶段内循环执行,直到最终报告生成。
在阶段一,用户输入研究需求,研究范围界定 Agent 会调用研究范围界定图,生成研究问题。
在阶段二,研究问题会传递给研究执行和报告撰写 Agent,然后该 Agent 会调用研究执行和报告撰写图,生成研究报告。
关于评估体系的构建,这里就不再详述了,大家可以参考我们开源仓库中的评估代码,其核心也是利用大模型的能力来进行评估。
总结与展望
至此,我们基础研究型 Agent 的核心构建之旅就告一段落了。但这仅仅是开始!
你可能会想,单个 Agent 的研究流程可能不够全面,如何让它变得更强大、更智能呢?这正是我们接下来要探索的:Research Supervisor(研究主管)和 Multi-Agent Research System(多Agent研究系统)!这些更酷的内容,我同样会更新到 Fairy 开源仓库中,最终打造一个终极的 Fairy 智能体。
感谢你的阅读!如果这篇文章让你对构建 Agent 有了新的启发,不妨去我们的 GitHub 仓库点亮一颗 Star ⭐ 吧!
https://github.com/codemilestones/Fairy
你的支持是我持续探索和分享的最大动力!我们下篇文章再见!👋